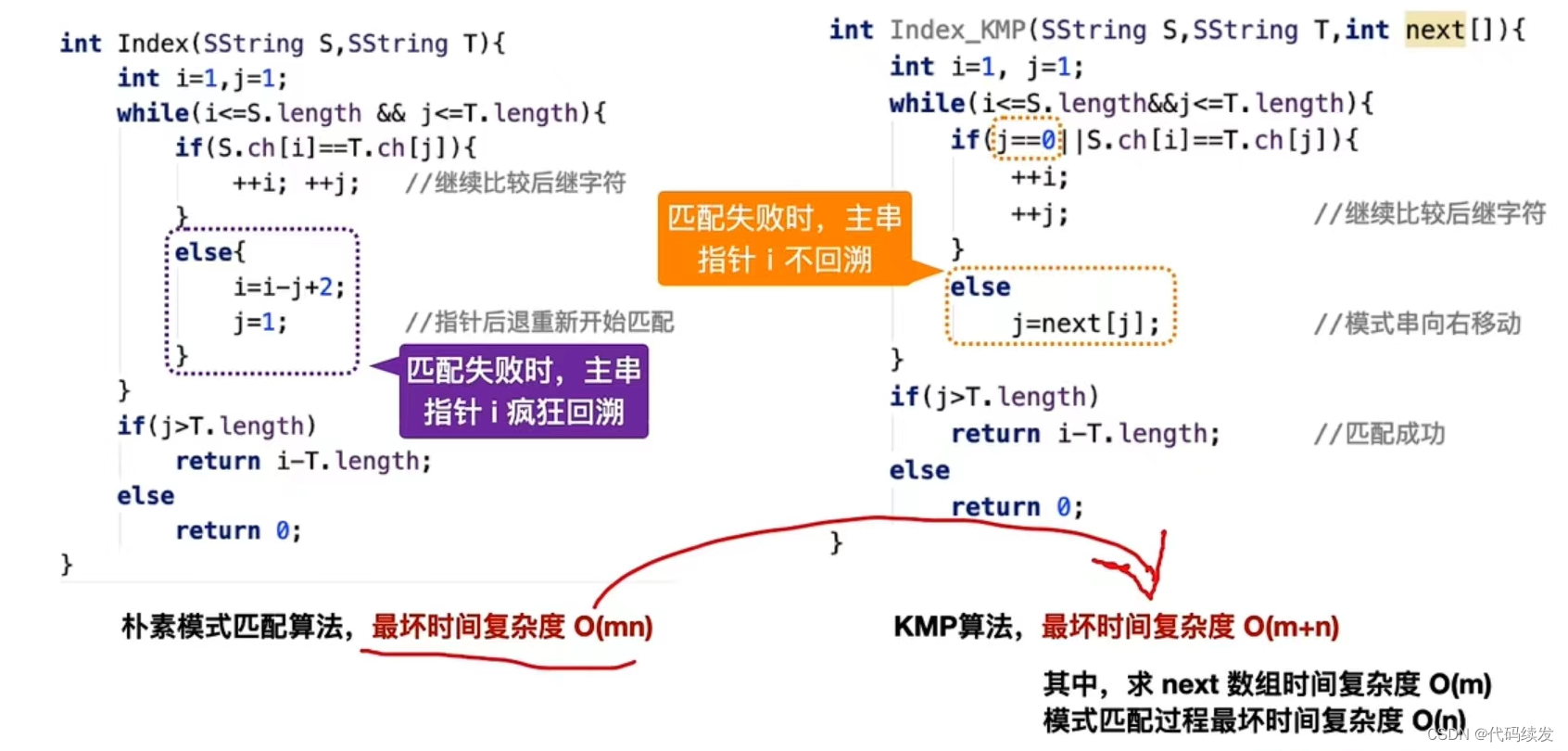
在运营商数据处理领域,Oracle存储过程一直是数据处理的核心工具,但随着技术的发展,寻找替代方案变得迫切。Kettle,作为Oracle存储过程的替代品,以其强大的功能和易用性,正逐渐受到运营商的青睐。本文将介绍Kettle的主要特性、实战应用,并提供案例分析,以帮助技术决策者了解Kettle的潜力,在面临类似问题提供宝贵的参考和借鉴。
PART.1 Kettle
Kettle,又称为Pentaho Data Integration,是一款强大的开源ETL(Extract, Transform, Load)工具,旨在帮助用户高效地处理和转换数据。
以下是kettle工具的六大特性:

对于那些习惯于使用存储过程的开发者来说,Kettle工具是一个非常合适的替代方案,总结起来有以下几点:
多平台支持:Kettle可在Windows、Linux、Mac OS X等操作系统上运行,便于跨平台开发。
界面化配置易上手:图形界面设计让操作直观,通过拖放组件构建ETL流程,无需编写复杂代码。
适配多种数据源:支持Oracle、MySQL、SQL Server、PostgreSQL等数据库,以及NoSQL数据库。
组件丰富功能强:提供大量预定义组件,覆盖数据处理的各个方面,减少编码复杂性。

组件库
调试功能强大:Kettle拥有一个综合日志系统,可以在执行过程中记录详细的信息。综合日志系统记录执行细节,可快速定位问题。

日志功能
PART.2 Kettle实战步骤
本章将详细介绍如何在实际应用中利用Kettle作为Oracle存储过程的替代方案,进行数据处理与转换。

实战步骤
01 应用安装
到官网下载对应的安装包,官网下载地址https://sourceforge.net/projects/pentaho/files/Data%20Integration。
由于是绿色版,下载后直接解压即可使用。文件目录结构如下。

文件目录示意
由于软件是基于JAVA语言开发的,需要在运行环境中安装JDK,JDK建议是1.8以上。
最后,点击运行Spoon.bat运行即可(linux系统下需要运行Spoon.sh)。
界面效果如下:
02 转换/作业开发调试
在Kettle中,数据处理主要通过作业(Job)和转换(Transformation)来完成,此章节将着重介绍作业和转换如何进行开发,怎么开展调试工作。

转换和作业
(1) 转换开发调试
首先,打开Kettle软件,并点击菜单中的“File -> New ->Transformation”来创建一个新的数据转换。
接着需要配置数据源,不同数据源的配置参数会稍有不同。配置完成后,可以点击“测试”按钮进行验证。
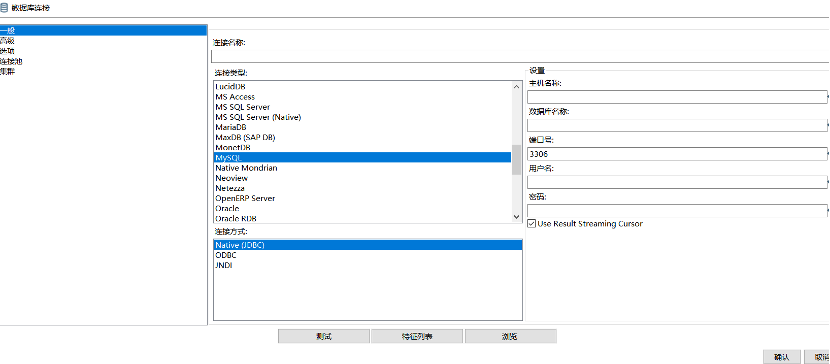
数据源配置
数据源配置完成后,就可以开始依照业务逻辑开始转换的开发工作了。首先先选择输入组件,如表输入。在弹出对话框中将所需要获取数据的语句写入。可通过“预览”按钮验证配置的是否正确。

数据库表获取范例
接着,可以利用Kettle提供的各种转换组件,如数据过滤、字段映射、计算字段、连接表等,对数据进行清洗和转换操作。

表关联查询范例
然后,将加工处理好的数据,通过输出组件沉淀到表或者文件中。
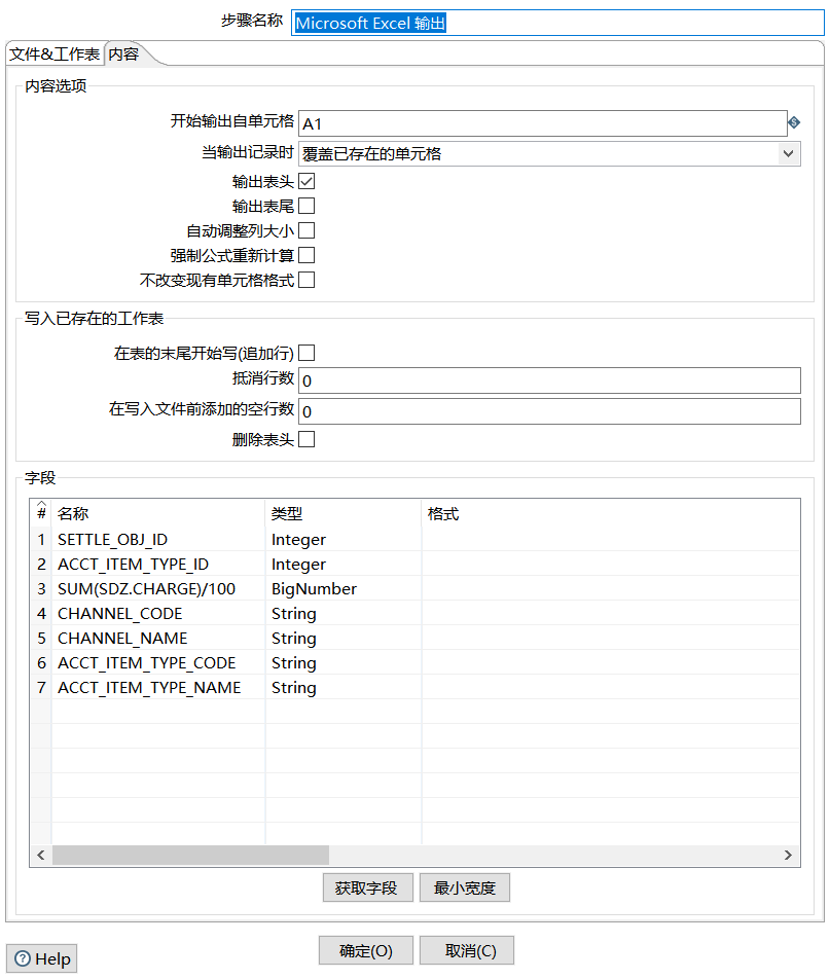
文件输出范例
这样就完成一个业务逻辑的开发工作了。最后,可以点击运行按钮,进行试运行。Kettle的日志系统会将每个步骤的运行情况以及耗时数据进行展示,方便使用人员进行核查和调试。
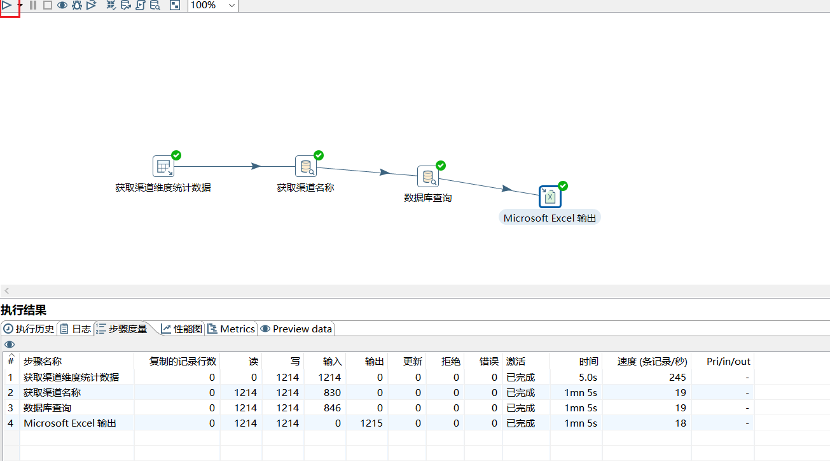
(2) 作业开发调试
如果有多个转换,而且转换之间有关联,则可以使用Kettle作业进行管理。
首先,点击菜单中的“File -> New -> Job”来创建一个新的作业。
接着,在“通用”中选择一个开始节点,开始节点作为起点。

通用组件
然后,就可以通过“转换”添加前面开发好的转换了。

转换配置
和转换类似,作业也提供了丰富的组件,可以满足大部分业务场景。

作业中的组件库
配置作业参数后,可以运行作业并监控执行过程,确保数据处理顺利进行。
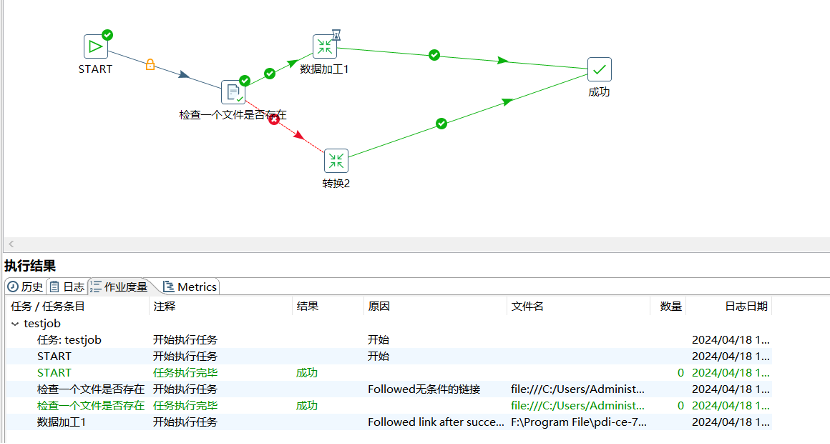
作业运行效果
03 保存资源库
kettle以资源库的形式存储所有重要数据指令和规则。它就像是一个信息中心,汇集了所有的作业(jobs)和转换(transformations)相关的细节。当需要执行某个任务时,Kettle的核心引擎会从这个资源库中读取所需的信息,然后按照指令进行操作,这个过程实现了在不同平台之间的无缝使用。
为了让每个人都能根据自己的需求选择适合自己的方式,Kettle提供了两种保存模式:文件模式和数据库模式。
-
文件模式就像是将作业和转换保存在电脑上的文件里。作业被保存在扩展名为.kjb的文件中,而转换则被保存在.ktr的文件中。这就像是给数据处理流程建立了一个文档化的档案。
-
数据库模式则是将这些信息存储在数据库中,具体来说,就是存放在R_TRANSFORMATION、R_JOB等数据库表中。这种方法适合于那些希望在数据库环境中管理作业和转换的用户,因为它可以提供更好的数据管理和访问控制。
无论选择哪种模式,Kettle的资源库都提供了一个便捷高效的方式来组织和管理数据处理任务,确保了工作的连贯性和可重复性。
04 Linux环境运行
在前面的章节中,已经介绍了如何在Windows平台上进行开发。现在,将介绍如何使用开发出的资源在Linux上运行的步骤。
首先,确保Linux环境上有安装JDK。接着将压缩包上传至Linux对应目录上,进行解压。
Kettle提供转换、工作两种命令启动方式。
☑️转换的命令启动格式
[opt@zte data-integration]$./pan.sh -rep=my_repo -user=admin -pass=admin -trans=stu1tostu2 -dir=/
参数说明:
-rep 资源库名称
-user 资源库用户名
-pass 资源库密码
-trans 要启动的转换名称
-dir 目录(不要忘了前缀 /)
☑️作业的命令启动格式
[opt@zte data-integration]$./kitchen.sh -rep=my_repo -user=admin -pass=admin -job=jobDemo1 -logfile=./logs/log.txt -dir=/
参数说明:
-rep - 资源库名
-user - 资源库用户名
-pass – 资源库密码
-job – job名
-dir – job路径
-logfile – 日志目录
PART.3 商用案例分享:酬金系统跨系统跨数据源汇聚
渠道酬金系统是第三方渠道为客户办理各类运营商产品和服务时,获得的报酬、奖励和补贴费用的结算系统。
随着运营商数据库国产化的推动,各省面临了替换Oracle存储过程的挑战,因此运维人员急需一种性能高、兼容性强的替代工具。通过研究和分析移动、电信运营商在相关省份的渠道酬金业务,总结出了一些关于Kettle开发流程的思路和方法,这些方法能够加快各省份在替换存储过程方面的进展。

01 数据源分析与整合
此阶段的目标是为了整合各个业务场景的关键数据,并整合最终酬金系统所需要的汇聚数据结构。这一步骤关键在于识别出数据的共通点和差异,以及各个数据的冗余和缺失情况。
首先,从CRM侧的https接口协议获取实时受理信息,分析出系统需求的关键信息包括订单标识、受理人工号、受理时间、受理业务。从计费侧梳理以表形式同步的数据为产品实例,其中包含了产品实例标识、用户号码、用户状态。渠道系统的数据以月度形式同步,同步形式为文件格式,包括渠道信息和渠道员工关系信息。
接着,分析渠道酬金业务结算所需要的关键字为,订单标识、产商品标识、受理号码、用户状态、受理人员工号、受理员工状态、受理渠道标识、受理渠道名称、归属本地网。将这些字段和各个系统数据源进行字段映射,判断是否满足要求。
最后,依照业务场景对数据进行检查,核对没有需要扩充的字段后,把基础业务数据表数据依照业务场景进行整合,形成汇聚数据设计图。

用户受理汇聚表设计图
02 设计ETL流程
基于数据汇聚设计图,设计ETL流程来处理数据抽取、转换和加载逻辑,并输出设计方案文档。方案文档包含需求分析内容、数据流设计、系统改造三个部分。需求分析章节将业务部门的原始需求进行写入,并进行分析。数据流设计则是将数据汇聚设计图写入,补充表模型以及建表语句。这里着重介绍系统改造部分。
系统改造包含两个部分,一个是数据源采集设计,即备注清楚CRM、计费、渠道的数据接口协议,以及对应的采集实现逻辑;第二个是将kettle的数据加工逻辑进行设计,主要是表关联,以及字段转换设计。由于CRM系统提供的订单通过https协议实时推送,这里需要单独设计一套客户端进行数据沉淀到酬金库表中。渠道接口的采集由于格式比较简单,可以直接沿用kettle的文件解析模块进行承接,如复杂一些的则可能需要单独开发对应的接口去实现,或者是通过开发kettle的插件实现。

用户受理汇聚需求设计
03 开发与测试
开发人员依照需求设计方案,在客户端上使用kettle进行开发ETL作业,并进行测试。
先配置数据源,用于读取CRM订单表和计费资料表数据。接着使用“表输入”插件,配置设计文档中定义好的查询SQL。利用“合并记录”插件通过产品标识字段将CRM和计费的表数据流进行合并,然后选择“文本文件输入插件”,将渠道文件解析格式写入,再用“合并记录”插件通过渠道标识字段将渠道数据流和前面的数据流进行合并。将合并的结果最终利用“表输入”插件,写入酬金汇聚表。这样数据加工流程就开发完成了,接着可以进行在线测试,核对并调优。
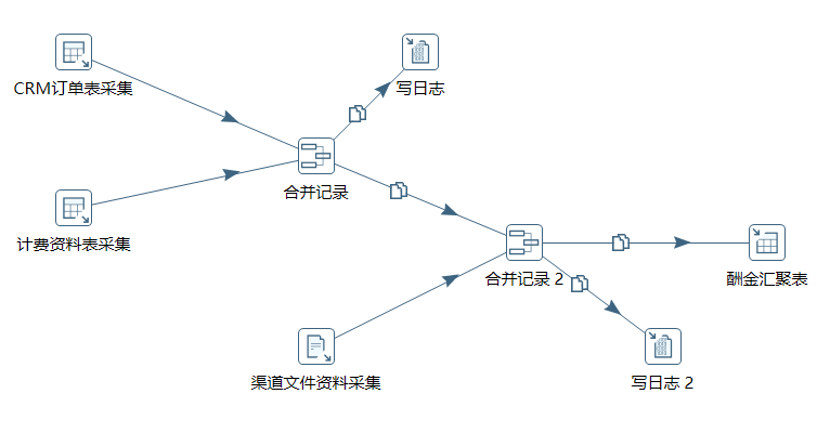
开发效果图
为了方便测试,可以使用“过滤记录”、“写日志”插件来进行在线调试。如过程中遇到流程问题可跳转至步骤2核对并修改设计逻辑后,再开发、测试。
04 部署与优化
在测试验证无误后,将ETL作业部署到生产环境。部署过程中,监控作业的执行效率和资源消耗,根据实际运行情况进行性能调优。例如,调整内存配置、优化数据库连接池设置等。

作业监控表格
05 监控与维护
运行期间,持续监控ETL作业的性能和数据质量。使用Kettle的日志记录和监控功能来跟踪作业执行情况,及时发现并解决运行中的问题。

监控维护表格
PART.4 结语
随着数据量的激增和处理需求的不断升级,Kettle作为一款强大的开源ETL工具,其在数据处理领域的重要性不言而喻。它不仅提供了一个易于使用的平台,让技术爱好者能够快速入门并实践数据操作,也为专业数据分析师和开发者提供了丰富的功能,以支持复杂的数据处理任务。
Kettle的灵活性、成本效益和社区支持,使其成为Oracle存储过程的一个强有力的替代方案。它的图形化界面降低了编程难度,而开源性质又保证了其可持续性和创新能力。
总之,Kettle不仅是一个现在的解决方案,更是一个未来的数据处理平台。随着技术的不断进步,它将继续适应并满足不同用户群体的需求,推动数据处理领域的创新和发展。


![[leetcode] 67. 二进制求和](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)